
Apache Sqoop Interview Questions And Answers – This interview Questions blog helps you in clearing all your queries and also helps you to crack your job interview. Here is the list of very frequently asked Sqoop Interview Questions from beginner to expert level by covering all the core areas by professionals from Codingcompiler .
So, let’s take a look…
Sqoop Interview Questions
1. What is Sqoop?
2. What are the different features of Sqoop?
3. Name a few import control commands
4. How can Sqoop handle large objects?
5. How can you import large objects like BLOB and CLOB in Sqoop?
6. What is the default file format to import data using Apache Sqoop?
7. How Sqoop Works?
8. What are the prerequisites to learn Apache Sqoop?
9. What is the Syntax used for Sqoop Import?
10. What is the Syntax used for Sqoop Export?
Basic Sqoop Interview Questions and Answers
1) What is Sqoop?
A) Sqoop − “SQL to Hadoop and Hadoop to SQL”
Apache Sqoop is an effective Hadoop tool used for importing data from RDBMS’s like MySQL, Oracle, etc. into HBase, Hive or HDFS. Sqoop Hadoop can also be used for exporting data from HDFS into RDBMS. Apache Sqoop is a command-line interpreter i.e. the Sqoop commands are executed one at a time by the interpreter.
2) What are the different features of Sqoop?
A) Here is the list of features supported by Sqoop
- Loading capacity
- Full Loading and Incremental Loading
- Data Compression Techniques
- Importing the SQL queries results
- Data Connectors for all the major databases
- Direct data loading support into Hadoop File Systems
- Security configurations like Kerberos
- Concurrent Import or Export functionalities
3) Name a few import control commands
Import control commands are used to import RDBMS data
Append: Append data to an existing dataset in HDFS. –append
Columns: columns to import from the table. –columns
• Where: where clause to use during import. —
4) How can Sqoop handle large objects?
The common large objects are Blog and Clob.Suppose the object is less than 16 MB, it is stored inline with the rest of the data. If there are big objects, they are temporarily stored in a subdirectory with the name _lob. Those data are then materialized in memory for processing. If we set lob limit as ZERO (0) then it is stored in external memory.
5) How can you import large objects like BLOB and CLOB in Sqoop?
The direct import function is not supported by Sqoop in case of CLOB and BLOB objects. Hence, if you have to import large purposes, you can use JDBC based imports. This can be done without introducing the direct argument of the import utility.
6) What is the default file format to import data using Apache Sqoop?
Sqoop allows data to be imported using two file formats. They are
- Delimited Text File Format
- Sequence File Format
Delimited Text File Format: This is the default file format to import data using Sqoop. This file format can be explicitly specified using the –as-textfile argument to the import command in Sqoop. Passing this as an argument to the command will produce the string based representation of all the records to the output files with the delimited characters between rows and columns.
Sequence File Format: It is a binary file format where records are stored in custom record-specific data types which are shown as Java classes. Sqoop automatically creates these data types and manifests them as java classes.
7) How Sqoop Works?
The following image shows the work flow of Sqoop
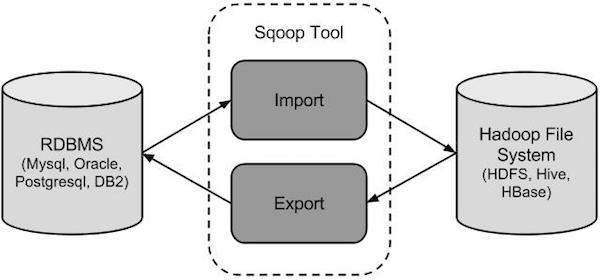
Sqoop Import
The import tool imports individual tables from RDBMS to HDFS. Each row in a table is treated as a record in HDFS. All records are stored as text data in text files or as binary data in Avro and Sequence files.
Sqoop Export
The export tool exports a set of files from HDFS back to an RDBMS. The files given as input to Sqoop contain records, which are called as rows in table. Those are read and parsed into a set of records and delimited with user-specified delimiter.
8) What are the prerequisites to learn Apache Sqoop?
In order to learn Apache Sqoop you need a basic knowledge of Core Java, Database concepts of SQL, Hadoop File system, and any of Linux operating system flavors.
9) What is the Syntax used for Sqoop Import?
The following syntax is used for Sqoop import
$ sqoop import (generic-args) (import-args)
10.What is the Syntax used for Sqoop Export?
The following syntax is used for Sqoop Export
$ sqoop export (generic-args) (export-args)
11) Name the relational databases supported in Sqoop?
- Sqoop currently supports
- MySQL
- PostgreSQL
- Oracle
- MSSQL
- Teradata and
- IBM’s Netezza as part of Relation Databases.
Sqoop uses MySQL as the default database.
12) Name the Hadoop eco-system sources supported in Sqoop?
Currently supported Hadoop Eco-system destination services are
1. HDFC
2. Hive
3. HBase
4. H Catalog and
5. Accumulo.
13) What are the Key Features of Sqoop?
There are 4 main key features of Sqoop
Bulk import:
Sqoop can import individual tables or entire databases into HDFS. The data is stored in the native directories and files in the HDFS file system.
Direct input:
Sqoop can import and map SQL (relational) databases directly into Hive and HBase.
Data interaction:
Sqoop can generate Java classes so that you can interact with the data programmatically.
Data export:
Sqoop can export data directly from HDFS into a relational database using a target table definition based on the specifics of the target database.
14) What is the role of JDBC Driver in Sqoop set up?
To connect to different relational databases sqoop needs a connector. Almost every DB vendor makes this connecter available as a JDBC driver which is specific to that DB. So Sqoop needs the JDBC driver of each of the database it needs to interact with.
The Best Sqoop Interview Questions From Experts
15) Is JDBC driver enough to connect sqoop to the databases?
No. Sqoop needs both JDBC and connector to connect to a database.
16) When to use –target-dir and when to use –warehouse-dir while importing data?
To specify a particular directory in HDFS use –target-dir but to specify the parent directory of all the sqoop jobs use –warehouse-dir. In this case under the parent directory sqoop will create a directory with the same name as the table.
17) Does Apache Sqoop have a default database?
Yes, MySQL is the default database.
18) How will you list all the columns of a table using Apache Sqoop?
Unlike sqoop-list-tables and sqoop-list-databases, there is no direct command like sqoop-list-columns to list all the columns. The indirect way of achieving this is to retrieve the columns of the desired tables and redirect them to a file which can be viewed manually containing the column names of a particular table.
Sqoop import –m 1 –connect ‘jdbc: sqlserver: //nameofmyserver; database=nameofmydatabase; username=DeZyre; password=mypassword’ –query “SELECT column_name, DATA_TYPE FROM INFORMATION_SCHEMA.Columns WHERE table_name=’mytableofinterest’ AND \$CONDITIONS” –target-dir ‘mytableofinterest_column_name’
19) How can we import data from particular row or column?
Sqoop allows to Export and Import the data from the data table based on the where clause. The syntax is
–columns
–where
–query
Example:
sqoop import –connect jdbc:mysql://db.one.com/corp –table INTELLIPAAT_EMP –where “start_date> ’2016-07-20’ ”
sqoopeval –connect jdbc:mysql://db.test.com/corp –query “SELECT * FROM intellipaat_emp LIMIT 20”
sqoop import –connect jdbc:mysql://localhost/database –username root –password aaaaa –columns “name,emp_id,jobtitle”
20) What is the destination types allowed in Sqoop import command?
Sqoop supports data imported into following services:
- HDFS
- Hive
- Hbase
- Hcatalog
- Accumulo
21) When to use –target-dir and when to use –warehouse-dir while importing data?
warehouse-dir points to the Hive folder to import data into (used while importing tables wholesale) while –target-dir is needed when importing into Hive via query (sqoop errs asking for it). In the latter scenario, it is used as a temporary area for the mappers to be followed by LOAD INPATH.
(or)
I.e; we use –target-dir to specify a particular directory in HDFS. Whereas we use –warehouse-dir to specify the parent directory of all the sqoop jobs. So, in this case under the parent directory sqoop will create a directory with the same name as the table.
22) Is Sqoop similar to distcp in Hadoop?
Both distCP (Distributed Copy in Hadoop) and Sqoop transfer data in parallel but the only difference is that distCP command can transfer any kind of data from one Hadoop cluster to another whereas Sqoop transfers data between RDBMS and other components in the Hadoop ecosystem like HBase, Hive, HDFS, etc.
23) How Sqoop can be used in java program?
You can run sqoop from inside your java code by including the sqoop jar in your classpath and calling the Sqoop.runTool() method. The necessary parameters should be created to Sqoop programmatically just like for command line.
24) What is the significance of using –compress-codec parameter?
To get the out file of a sqoop import in formats other than .gz like .bz2 we use the –compress -code parameter.
Advanced Sqoop Interview Questions and Answers
25) How can you check all the tables present in a single database using Sqoop?
The command to check the list of all tables present in a single database using Sqoop is as follows-
Sqoop list-tables –connect jdbc: mysql: //localhost/user;
26) How can you choose a name for the mapreduce job which is created on submitting a free-form query import?
sqoop import \
–connect jdbc:mysql://mysql.example.com/sqoop \
–username sqoop \
–password sqoop \
–query ‘SELECT normcities.id, \
countries.country, \
normcities.city \
FROM normcities \
JOIN countries USING(country_id) \
WHERE $CONDITIONS’ \
–split-by id \
–target-dir cities \
–mapreduce-job-name normcities
27) How will you implement all-or-nothing load using sqoop?
According to the Sqoop user guide, in order to perform an “all-or-nothing” load into a RDMS, a staging table can be used. And then load it to the final target table only if the staging load is successful. However, this option only seems to be available in exports. When performing an import (from SQLServer) into HDFS, the option –staging-table is not present.
28) To prevent the password from being mentioned in the sqoop import clause we can use the additional parameters
The -P option asks for password from standard input without echoing and –password-file option reads the password value stored in some other file.
29) What is the compression mechanism used by Sqoop?
Sqoop does not have any inbuilt code to carry out file compression. It relies on Hadoop’s compression settings.
30) How can you schedule a sqoop job using Oozie?
Oozie has in-built sqoop actions inside which we can mention the sqoop commands to be executed.
31) How can we import a subset of rows from a table without using the where clause?
We can run a filtering query on the database and save the result to a temporary table in database.
Then use the sqoop import command without using the –where clause.
32) What is the default extension of the files produced from a sqoop import using the –compress parameter?
.gz
33) What is the advantage of using –password-file rather than -P option while preventing the display of password in the sqoop import statement?
The –password-file option can be used inside a sqoop script while the -P option reads from standard input, preventing automation.
34) How can you sync a exported table with HDFS data in which some rows are deleted?
Truncate the target table and load it again.
35) What do you mean by Free Form Import in Sqoop?
Sqoop can import data from a relational database using any SQL Query rather than only using table and column name and parameters.
Related Interview Questions
- Apigee Interview Questions
- Cloud Foundry Interview Questions And Answers
- Actimize Interview Questions
- Kibana Interview Questions
- Nagios Interview Questions
- Jenkins Interview Questions
- Chef Interview Questions
- Puppet Interview Questions
- DB2 Interview Questions
- AnthillPro Interview Questions
- Angular 2 Interview Questions
- Hibernate Interview Questions
- ASP.NET Interview Questions
- PHP Interview Questions
- Kubernetes Interview Questions
- Docker Interview Questions
- CEH Interview Questions
- CyberArk Interview Questions
- Appian Interview Questions
- Drools Interview Questions
- Talend Interview Questions
- Selenium Interview Questions
- Ab Initio Interview Questions
- AB Testing Interview Questions
- Mobile Application Testing Interview Questions
- Pega Interview Questions
- UI Developer Interview Questions
- Tableau Interview Questions
- SAP ABAP Interview Questions
- Reactjs Interview Questions
- UiPath Interview Questions
- Mean Stack Interview Questions